
How to Automatically Transcribe Audio Like a Pro using AI Tools and APIs
Contents
Transcription isn't just about converting spoken language into written text, it unlocks the true potential of audio content. It makes interviews, podcasts, meetings, and other audio recordings accessible to people with hearing impairments, helps them reach a global audience, and enables the audience to find specific information without listening to the entire recording.
In this article, we will explore what transcription is, how to transcribe audio, and what tools you can use to do it automatically.
What Does Transcribe Mean?
To transcribe means to convert audio or video content into written text. It can be accomplished manually by an individual, or automatically using specialized transcription software/applications.
In manual transcription, a person actively listens to the audio or video and meticulously types out what they hear. While this method is time-consuming, it ensures a high level of accuracy. With automated transcription, you simply submit the media file to a transcription application, which generates the written text automatically. This method is significantly faster, but it may introduce errors. The transcription application might also struggle with accents, background noise, or complex terminology.
How to Transcribe Audio
Transcribing audio may seem daunting, but it can be simple. Let's break it down into a few steps:
Step 1. Prepare Your Audio File
Begin by gathering the audio file you want to transcribe. It could be in various formats like MP3, WAV, and more. For optimal results, ensure that the audio quality is clear and free from excessive background noise.
Step 2. Choose Your Transcription Method
You can transcribe the audio manually or using an auto-transcription application:
- Manual transcription : Listen to the audio and type out the spoken content manually. Using a headphone can help you block out external noise and catch subtle details that might be missed when using speakers.
- Auto-transcription: Use specialized transcription tools or services to auto-generate the text. These tools analyze the audio and generate a written transcript automatically for you. We will discuss them later in the article.
Step 3. Add Timestamps
Adding timestamps to your transcriptions can be immensely helpful for editing or referencing specific parts of the audio. You can insert timestamps at regular intervals or when there's a significant change in content. For example, [5:01] This is an example of how to transcribe audio. This makes it easier to navigate and work with the transcript.
Step 4. Proofread and Edit
Finally, review your transcription for accuracy, grammar, and spelling errors. Proofreading and editing are essential to provide a polished and error-free transcript. Ensure that the formatting is consistent throughout the transcribed text too!
Tools for Transcribing Audio Automatically
Various auto-transcription applications and APIs can help you streamline the transcription process and enhance accuracy. Here are some popular options:
Amazon Transcribe
Amazon Transcribe is an automatic speech recognition (ASR) service provided by Amazon Web Services (AWS). You can transcribe audio (and videos!) into text in real-time using their built-in voice recorder, or create a transcription job and upload the audio file. However, the file needs to be uploaded to an AWS S3 bucket.
Here’s an example of the transcription result:
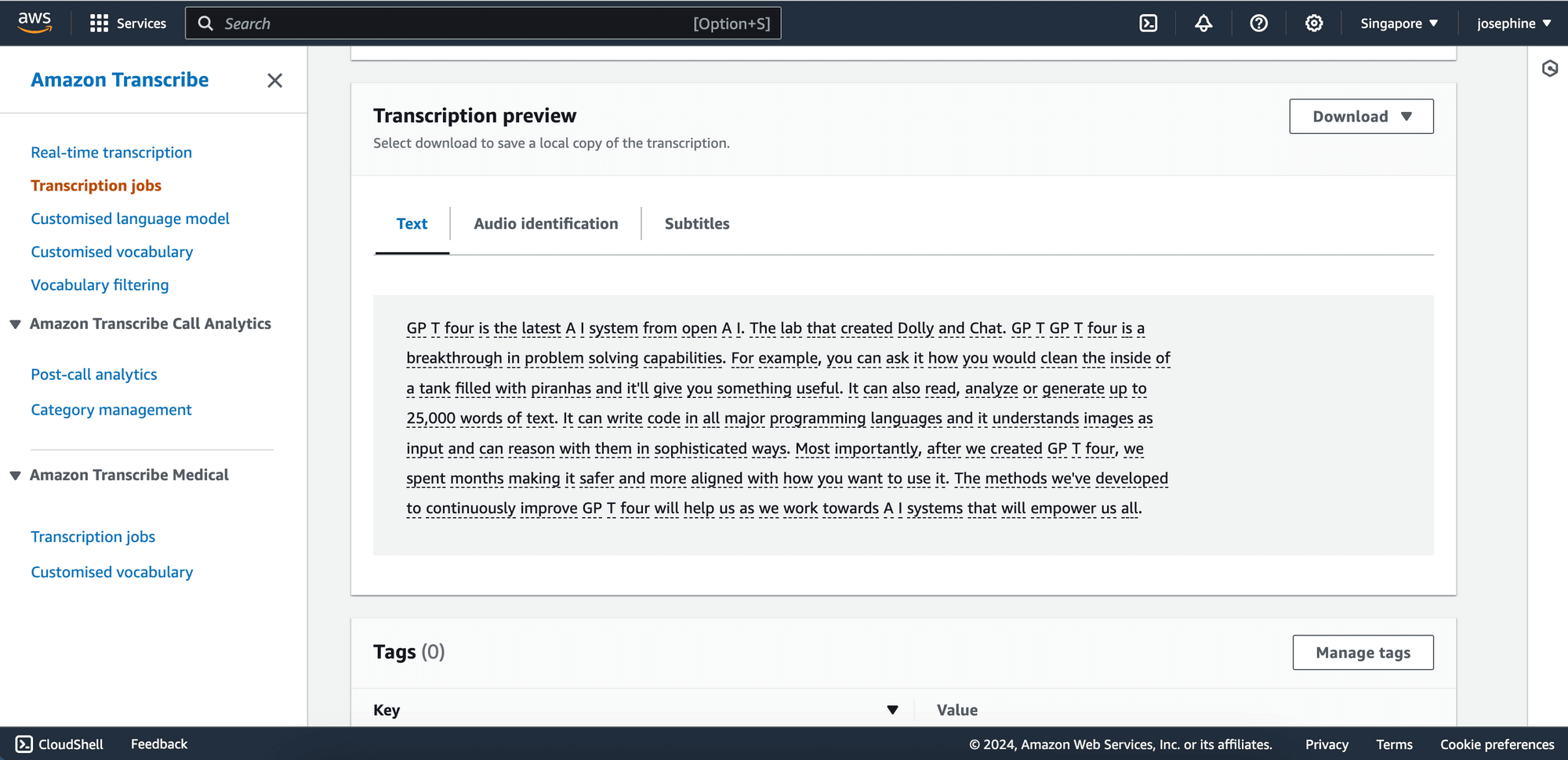
You can also send an API request to transcribe the audio instead of using the dashboard. This allows you to integrate the functionality into your application or project.
Furthermore, Amazon Transcribe offers specialized transcription extended from its basic transcription service:
- Amazon Transcribe Call Analytics - This service uses models that are trained to specifically understand customer service and sales calls. It can generate highly accurate call transcripts and extract conversation insights to help improve customer experience.
- Amazon Transcribe Medical - It specializes in transcribing medical terminologies such as medicine names, procedures, conditions, and diseases that are difficult to transcribe using other general speech-to-text services. It can transcribe conversations between doctors and patients for documentation purposes, add subtitles for telehealth consultations, and more.
- Amazon Transcribe Toxicity Detection - Amazon Transcribe Toxicity Detection is a voice-based toxicity detection tool that can identify and classify toxic language. It can detect hate speech, harassment, and threats from not only words but also the speech’s tone and pitch.
| | |
| — | — |
| Key Features | - Real-time transcription
- Batch transcription
- Domain-specific models
- Automatic language identification
- Automatic content redaction / PII redaction
- Toxic audio content detection |
| User Interface | ✅ |
| API | ✅ |
| Pricing | from *$0.00780/min (60 minutes free per month for 12 months)
*The price is for the East US, pricing rates vary by region. |
🐻 Bear Tips: For best results, use a lossless format, such as FLAC or WAV with PCM 16-bit encoding.
Google Cloud Speech-to-Text
Google Cloud Speech-to-Text is a speech-to-text service that uses advanced AI models to transcribe audio to text, and it supports over 125 languages! Besides transcribing audio from the Google Cloud console, you can also use their SDKs (Go, Java, Node.js, Python, etc.), call the REST APIs, or use the Google Cloud CLI (gcloud).
Here’s a screenshot of the Google Cloud console where you can upload your audio file and get it transcribed:
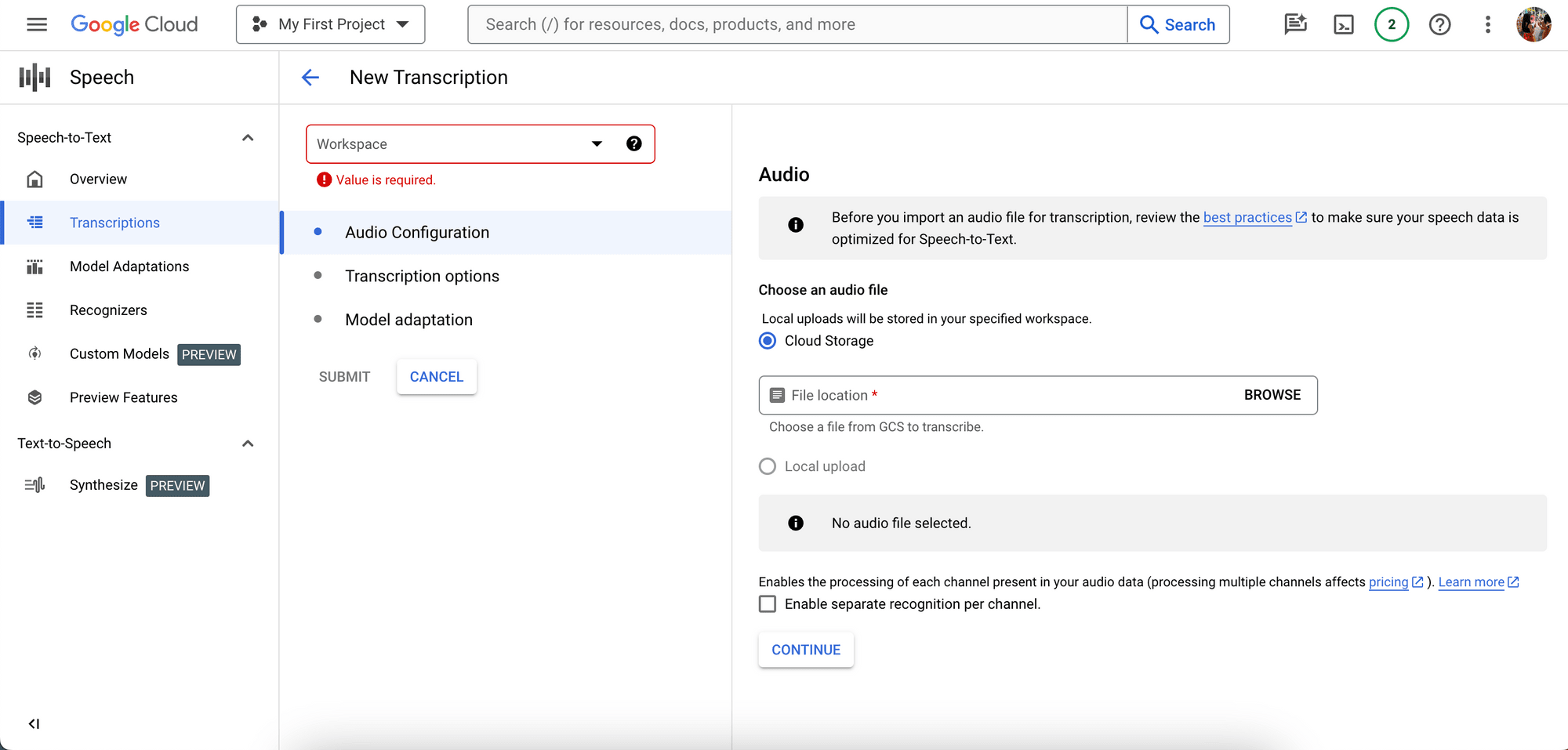
Google Cloud Speech-to-Text offers domain-specific transcription models that are optimized for domain-specific quality requirements, like phone_call, medical_dictation, medical_conversation, video, and more. You can also specify words and/or phrases that are special, rare, or where the audio contains noise. This is called model adaptation and helps to improve the transcription’s accuracy.
Despite being one of the Google Cloud products, you can deploy it on your own infrastructure instead of using the Cloud version. This allows you to protect your audio data when using Google Cloud Speech-to-Text.
| | |
| — | — |
| Key Features | - Support for 125 languages and variants
- Real-time speech recognition
- Domain-specific models
- Customize speech recognition to transcribe domain-specific terms and rare words
- Recognize distinct channels in multichannel situations
- Gives enterprise and business customers added security and regulatory requirements out of the box |
| User Interface | ✅ |
| API | ✅ |
| Pricing | from $0.016/min (60 minutes free per month) |
🐻 Bear Tips: Google Docs and Google Meet offer built-in voice typing features for Google Workspace users. You can speak into the microphone and get your audio transcribed into text within the apps.
Whisper
Whisper is an automatic speech recognition (ASR) system developed by OpenAI. The AI model has been trained on 680,000 hours of multilingual and multitask supervised data collected from the web, to transcribe and translate audio (via the transcriptions and translations endpoints). However, OpenAI doesn’t offer direct access to the Whisper model for all users. To use it within the ChatGPT interface, you’ll need a ChatGPT Plus subscription and get custom GPTs from the marketplace:
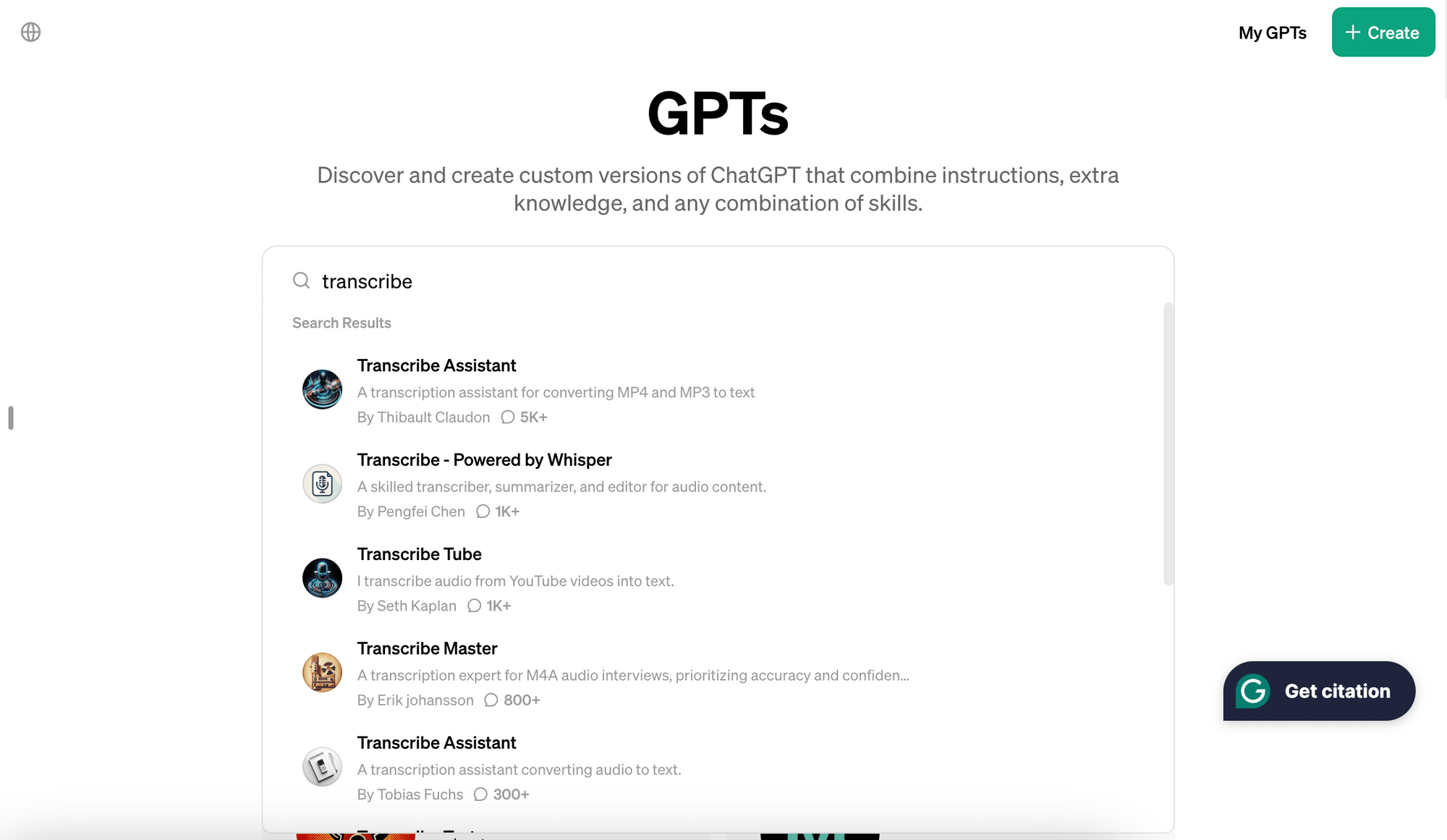
That said, you can access the Whisper speech-to-text model without a ChatGPT Plus subscription—by using the API.
To access the Whisper API, you can make an HTTP request to the endpoint or use the libraries for any of the supported languages (e.g. Node.js, Python, Java, etc.). Here’s an example of using the Node.js library:
import fs from "fs";
import OpenAI from "openai";
const openai = new OpenAI();
async function main() {
const transcription = await openai.audio.transcriptions.create({
file: fs.createReadStream("/path/to/file/audio.mp3"),
model: "whisper-1",
});
console.log(transcription.text);
}
main();
The Whisper model can transcribe in up to 60 languages, including English, Chinese, Arabic, Hindi, and French. Besides that, it can also transcribe audio in any of the supported languages into English automatically. For example, if you have an audio clip in French, Whisper can transcribe and translate it into English text.
| | |
| — | — |
| Key Features | - Customizable voices and models
- Flexible deployment (in the cloud or using containers)
- Enterprise-grade reliability and performance
- Automatically format and punctuate transcriptions for readability
- Adheres to rigorous security standards (SOC, FedRAMP, PCI DSS, HIPAA, HITECH, and ISO) |
| User Interface | ✅ (ChatGPT Plus) |
| API | ✅ |
| Pricing | Start for free and from *$0.36/hour for standard features
*The price is for the Central US, pricing rates vary by region. |
🐻 Bear Tips: Besides the official Node.js and Python libraries, there are more than 20 community-maintained libraries for other programming languages.
Azure AI Speech
Azure AI Speech is a managed service by Microsoft that offers industry-leading AI speech capabilities. It is part of Azure AI Services, a collection of customizable, prebuilt AI models that can be used to add AI to applications.
Azure AI Speech can quickly and accurately transcribe audio to text in more than 100 languages and variants. For some languages and base models, you can also customize and build your own speech-to-text models to improve transcription accuracy. You can upload audio together with human-labeled transcripts, plain text, structured text, or pronunciation data, to help Azure AI Speech recognize specific words.
You can transcribe speech from various sources using Azure AI Speech, including microphones, audio files, and blob storage. The transcriptions will be formatted automatically with punctuation.
| | |
| — | — |
| Key Features | - Customizable voices and models
- Flexible deployment (in the cloud or using containers)
- Enterprise-grade reliability and performance
- Automatically format and punctuate transcriptions for readability
- Adheres to rigorous security standards (SOC, FedRAMP, PCI DSS, HIPAA, HITECH, and ISO) |
| User Interface | ✅ |
| API | ✅ |
| Pricing | Start for free and from *$0.36/hour for standard features
*The price is for the Central US, geographical pricing is implemented. |
🐻 Bear Tips: Azure AI Speech also supports text-to-speech, speech translation, and speaker recognition.
AssemblyAI
AssemblyAI is a company that specializes in Speech AI models. It offers the Speech-to-Text API for transcribing speech to text and accurately analyzing the content.
One of its analysis capabilities is identifying different speakers during a conversation. Using the Speaker Diarization model, it can detect multiple speakers in an audio file and what each speaker says. If you know the number of speakers in the audio, you can specify it to further improve the accuracy.
Here’s an example of the transcription result with the speakers identified:
Speaker A: Smoke from hundreds of wildfires in Canada is triggering air quality alerts throughout the US. Skylines from Maine to Maryland to Minnesota are gray and smoggy. And in some places, the air quality warnings include the warning to stay inside. We wanted to better understand what's happening here and why, so we called Peter DiCarlo, an associate professor in the Department of Environmental Health and Engineering at Johns Hopkins University. Good morning, professor.
Speaker B: Good morning.
Speaker A: So what is it about the conditions right now that have caused this round of wildfires to affect so many people so far away?
Speaker B: Well, there's a couple of things. The season has been pretty dry already, and then the fact that we're getting hit in the US. Is because there's a couple of weather systems that are essentially channeling the smoke from those Canadian wildfires through Pennsylvania into the Mid Atlantic and the Northeast and kind of just dropping the smoke there.
Speaker A: So what is it in this haze that makes it harmful? And I'm assuming it is.
...
Source: AssemblyAI
Besides that, it can also analyze the emotional tone of spoken content. This helps to understand sentiments expressed in calls, podcasts, or other voice data.
| | |
| — | — |
| Key Features | - >90% accuracy
- Real-time transcription with low latency and high-quality
- Highly scalable-async transcription for tens of thousands of files in parallel
- Automatically detect and replace profanity in the transcription text
- Automatically redact sensitive information (PII Redaction)
- Segment audio into chapters automatically |
| User Interface | ❌ |
| API | ✅ |
| Pricing | from $0.37/hour |
Transcribing Audio of a Video File
Transcribing audio of a video file follows similar steps but you need to extract audio from the video first using tools like FFmpeg. Then, transcribe the extracted audio using the tools mentioned earlier (some of them support transcribing videos too).
Besides that, you can use automated media generation tools like Bannerbear. It transcribes videos and adds customizable closed captions/subtitles automatically to make the video content more accessible and engaging.
The subtitles’ font style and color can be customized from Bannerbear’s template editor:

Here’s an example of a video transcribed and subtitled using Bannerbear:
🐻 Bear Tips: You can sign up for a Bannerbear account for free!
Conclusion
Transcription plays a crucial role in making audio content accessible to a wider audience, including those who don’t understand the spoken language or with hearing impairments. Whether you choose to transcribe manually or use transcription applications like those mentioned in this article, it sure can significantly enhance the accessibility and utility of your audio content!
